实验室动态NEWS

-
 2025.10.2110月17日,农工党南京邮电大学基层委员会与农工党南京医科大学第二附属医院东院支部医工交叉创新研讨会在南邮三牌楼校区圆满召开。会议旨在促进医学与工学的深度对话与协作,探索“健康中国”战略背景下科技创新与医疗服务的融合路径,来自两个基层组织的二十位专家学者参会。参观智通实验室 在农工党南邮基层委党员、智通实验室主任郭永安教授的陪同下,专家们实地参观了解了智通实验室的发展历程、科研环境与创新成果,并就相关技术应用进行了深入交流。农工党省委原专职副主委、高质量发展评价研究院基层治理与民生保障专委会主任 吴建坤农工党南邮基层委员会主委 刘胜利 随后,研讨会在热烈而务实的气氛中拉开帷幕。农工党省委原专职副主委、高质量发展评价研究院基层治理与民生保障专委会主任吴建坤,农工党南邮基层委员会主委刘胜利先后致辞,他们一致指出,随着科技革命的深入推进,医工交叉已成为推动医疗事业发展的核心引擎。南京邮电大学在信息与通信技术、人工智能、大数据及物联网等领域的科研实力,与南京医科大学第二附属医院东院丰富的临床资源、迫切的现实应用需求高度互补。本次交流是农工党基层组织发挥界别优势,积极服务社会发展的
2025.10.2110月17日,农工党南京邮电大学基层委员会与农工党南京医科大学第二附属医院东院支部医工交叉创新研讨会在南邮三牌楼校区圆满召开。会议旨在促进医学与工学的深度对话与协作,探索“健康中国”战略背景下科技创新与医疗服务的融合路径,来自两个基层组织的二十位专家学者参会。参观智通实验室 在农工党南邮基层委党员、智通实验室主任郭永安教授的陪同下,专家们实地参观了解了智通实验室的发展历程、科研环境与创新成果,并就相关技术应用进行了深入交流。农工党省委原专职副主委、高质量发展评价研究院基层治理与民生保障专委会主任 吴建坤农工党南邮基层委员会主委 刘胜利 随后,研讨会在热烈而务实的气氛中拉开帷幕。农工党省委原专职副主委、高质量发展评价研究院基层治理与民生保障专委会主任吴建坤,农工党南邮基层委员会主委刘胜利先后致辞,他们一致指出,随着科技革命的深入推进,医工交叉已成为推动医疗事业发展的核心引擎。南京邮电大学在信息与通信技术、人工智能、大数据及物联网等领域的科研实力,与南京医科大学第二附属医院东院丰富的临床资源、迫切的现实应用需求高度互补。本次交流是农工党基层组织发挥界别优势,积极服务社会发展的 -
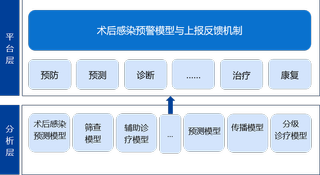
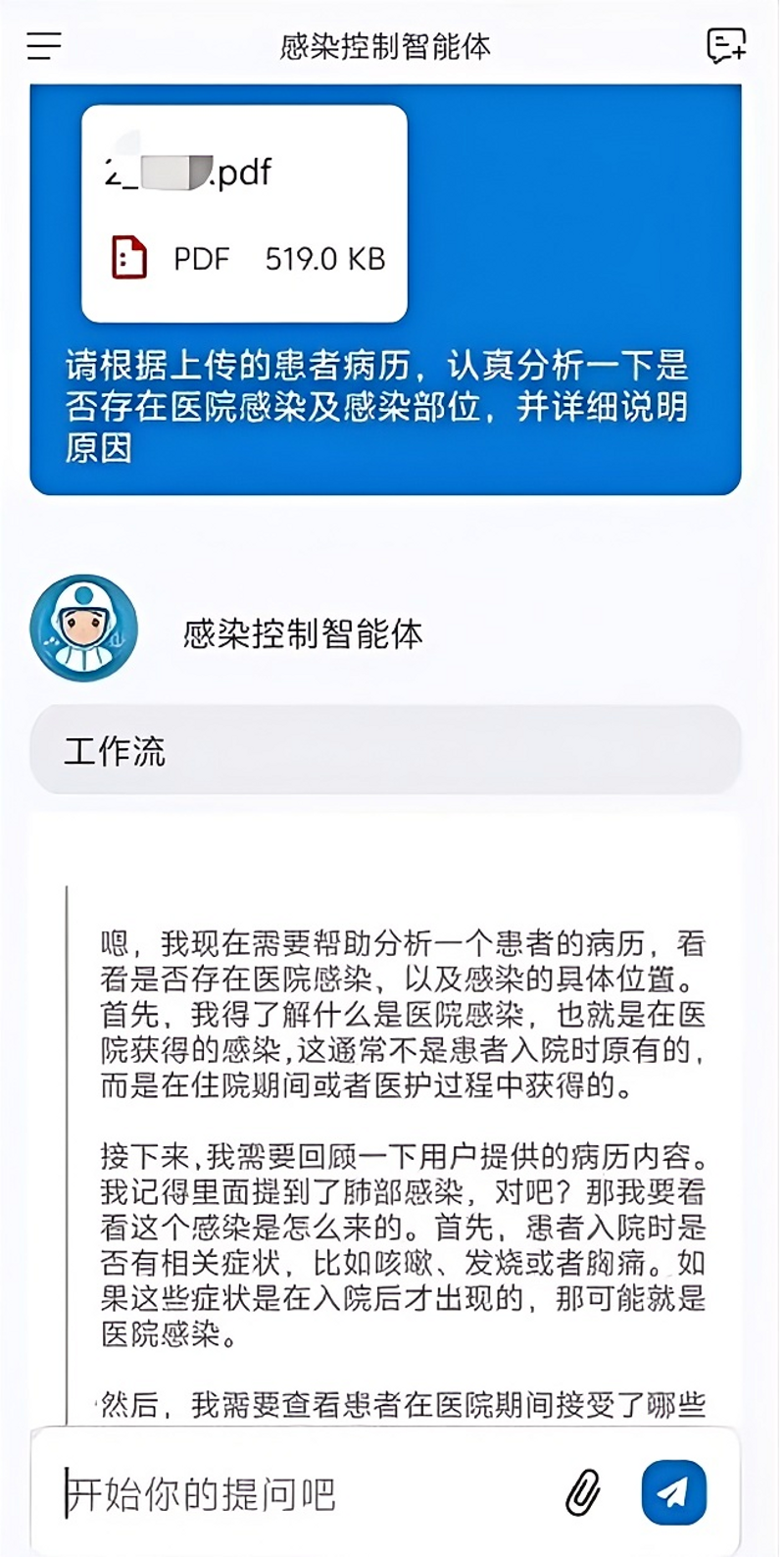 2025.03.12感染控制智能体 为全面提升医院感染管理智能化水平,近日,江苏省人民医院感染管理处在信息处的大力协助下,与南京邮电大学边缘智能研究院合作,依托讴谛医疗大模型系统,成功构建“感染控制智能体”。 通用大模型(如ChatGPT等)在解决行业专业问题时存在一定局限性,行业大模型才是今后行业应用落地的重点。通过基于DeepSeek大模型的深度语义理解与动态推理能力,创新引入RAG(Retrieval-Augmented Generation,检索增强生成)技术,构建了覆盖最新、最全的行业规范、指南、标准、专家共识和临床案例知识库,通过动态检索最新文献与院内数据库,实时更新知识库,使系统在技术咨询、辅助诊断、感染预警、策略建议、科研设计及论文撰写等工作时,既能发挥大模型的逻辑推理优势,又能通过精准检索确保结论与最新指南同步更新,同时还能符合医院个性化要求。 感染控制智能体将人工智能技术应用于感染控制,显著提高感染防控的精准性和工作效率,助力医疗质量提升,为患者与医务人员的健康筑牢坚实防线。未来将不断提升其功能和性能,使其具备性能更强、场景适宜的智能化分析与应对能力。感控智造也将为医疗行业人工智能化进
2025.03.12感染控制智能体 为全面提升医院感染管理智能化水平,近日,江苏省人民医院感染管理处在信息处的大力协助下,与南京邮电大学边缘智能研究院合作,依托讴谛医疗大模型系统,成功构建“感染控制智能体”。 通用大模型(如ChatGPT等)在解决行业专业问题时存在一定局限性,行业大模型才是今后行业应用落地的重点。通过基于DeepSeek大模型的深度语义理解与动态推理能力,创新引入RAG(Retrieval-Augmented Generation,检索增强生成)技术,构建了覆盖最新、最全的行业规范、指南、标准、专家共识和临床案例知识库,通过动态检索最新文献与院内数据库,实时更新知识库,使系统在技术咨询、辅助诊断、感染预警、策略建议、科研设计及论文撰写等工作时,既能发挥大模型的逻辑推理优势,又能通过精准检索确保结论与最新指南同步更新,同时还能符合医院个性化要求。 感染控制智能体将人工智能技术应用于感染控制,显著提高感染防控的精准性和工作效率,助力医疗质量提升,为患者与医务人员的健康筑牢坚实防线。未来将不断提升其功能和性能,使其具备性能更强、场景适宜的智能化分析与应对能力。感控智造也将为医疗行业人工智能化进


学术活动ACADEMIC ACTIVITIES
社会服务SOCIAL SERVICE
-
2024-09-10
-
2024-07-18
-
2024-06-21
-
2024-04-29
-
2024-04-29
-
2024-04-29